Deobfuscating Javascript via AST: Reversing Various String Concealing Techniques
Preface
This article assumes a preliminary understanding of Abstract Syntax Tree structure and BabelJS. Click Here to read my introductory article on the usage of Babel.
What is String Concealing?
In JavaScript, string concealing is an obfuscation technique that transforms code in a way that disguises references to string literals. After doing so, the code becomes much less readable to a human at first glance. This can be done in multiple different ways, including but not limited to:
- Encoding the string as a hexadecimal/Unicode representation,
- Splitting a single string into multiple substrings, then concatenating them,
- Storing all string literals in a single array and referencing an element in the array when a string value is required
- Using an algorithm to encrypt strings, then calling a corresponding decryption algorithm on the encrypted value whenever its value needs to be read
In the following sections, I will provide some examples of these techniques in action and discuss how to reverse them.
Examples
Example #1: Hexadecimal/Unicode Escape Sequence Representations
Rather than storing a string as a literal, an author may choose to store it as an escape sequence. The javascript engine will parse the actual string literal value of an escaped string before it is used or printed to the console. However, it’s virtually unreadable to an ordinary human. Below is an example of a sample obfuscated using this technique.
Original Source Code
1 | |
Post-Obfuscation Code
1 | |
Analysis Methodology
Despite appearing daunting at first glance, this obfuscation technique is relatively trivial to reverse. To begin, let’s copy and paste the obfuscated sample into AST Explorer
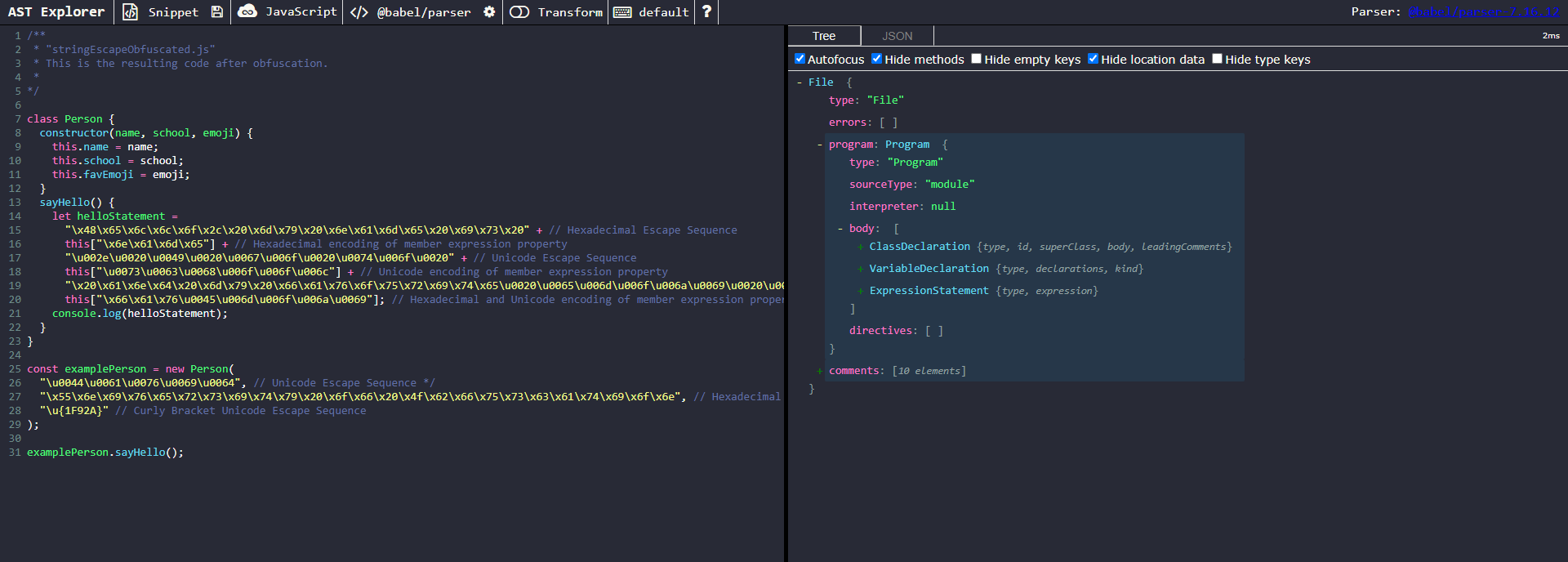
Our targets of interest here are the obfuscated strings, which are of type StringLiteral. Let’s take a closer look at one of these nodes:
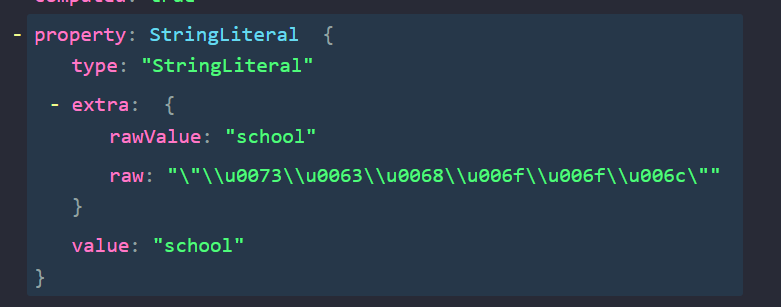
We can deduce two things from analyzing the structure of these nodes:
- The actual, unobfuscated value has been parsed by Babel and is stored in the value property.
- All nodes containing escaped text sequences have a property, extra which store the actual value and encoded text in extra.rawValue and extra.raw properties respectively
Since the parsed value is already stored in the value property, we can safely delete the extra property, causing Babel to default to the value property when generating the code and thereby restoring the original strings. To do this, we create a visitor that iterates through all StringLiteral_to nodes to delete the **_extra** property if it exists. After that, we can generate code from the resulting AST to get the deobfuscated result. The babel implementation is shown below:
Babel Deobfuscation Script
1 | |
After processing the obfuscated script with the babel plugin above, we get the following result:
Post-Deobfuscation Result
1 | |
The strings are now deobfuscated, and the code becomes much easier to read.
Example #2: String-Array Map Obfuscation
This type of obfuscation removes references to string literals and places them in a special array. Whenever a value must be accessed, the obfuscated script will reference the original string’s position in the string array. This technique is often combined with the previously discussed technique of storing strings as hexadecimal/unicode escape sequences. To isolate the point in this example, I’ve chosen not to include additional encoding. Below is an example of this obfuscation technique in practice:
Original Source Code
1 | |
Post-Obfuscation Code
1 | |
Analysis Methodology
Similar to the first example, this obfuscation technique is mostly for show and very trivial to undo. To begin, let’s copy and paste the obfuscated sample into AST Explorer
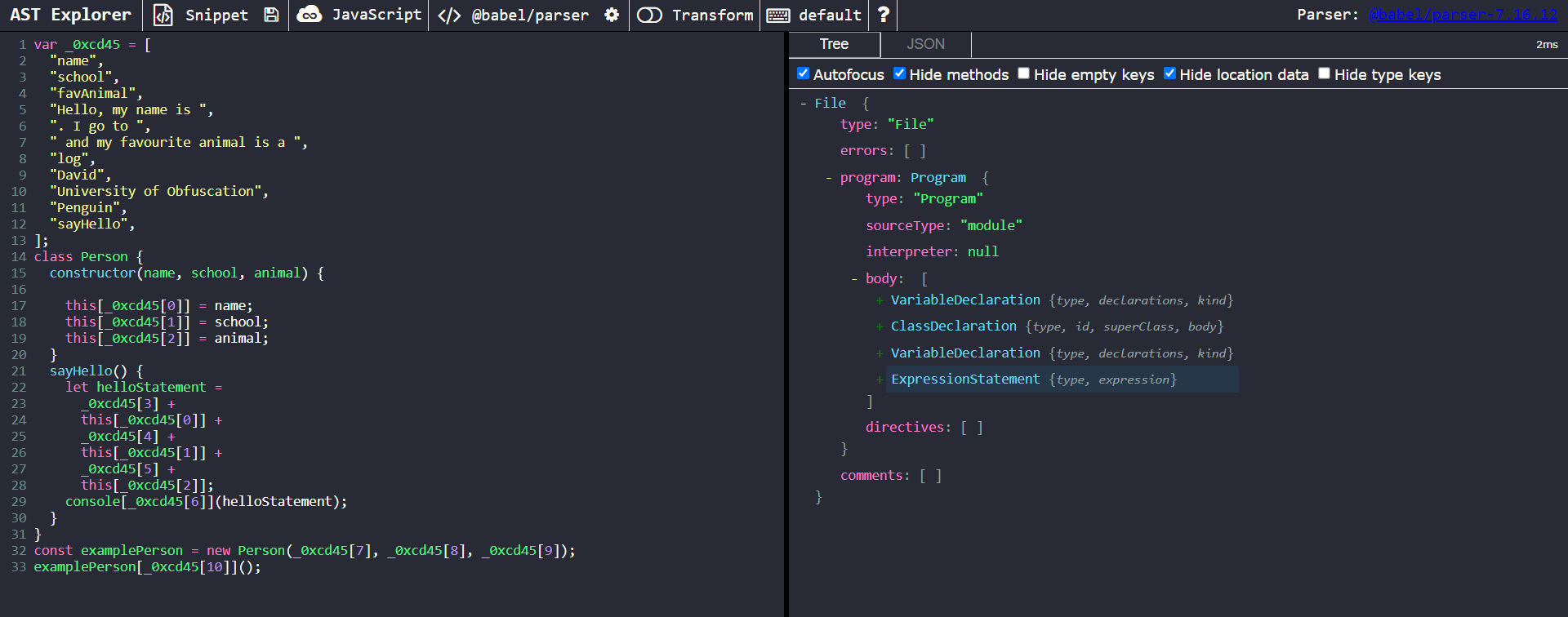
Our targets of interest here are the master array, _0xcd45 and its references. These references to it are of type MemberExpression. Let’s take a closer look at one of the MemberExpression nodes of interest.
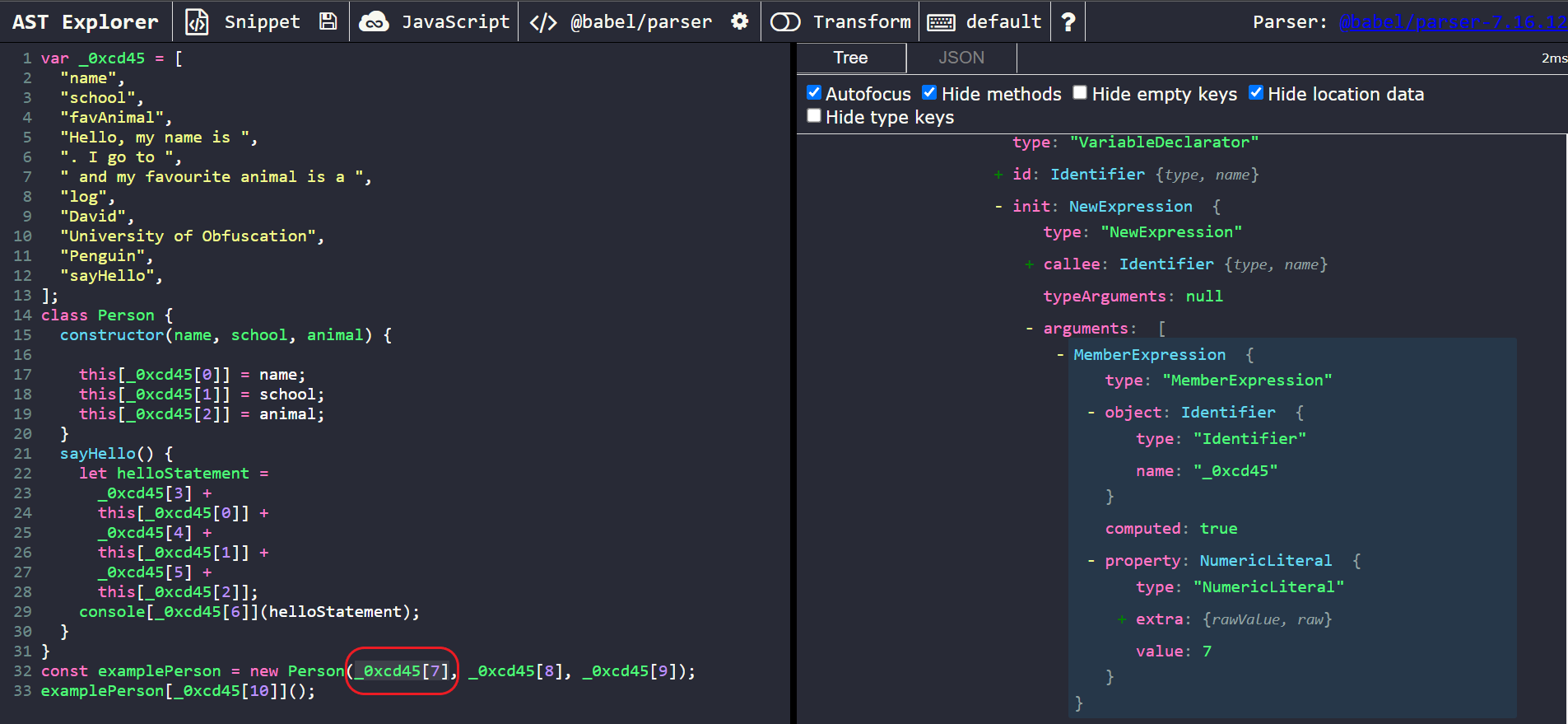
We can notice that, unlike the first example, babel does not compute the actual value of these member expressions for us. However, it does store the name of the array they are referencing and the position of the array to be accessed.
Let’s now expand the VariableDeclaration node that holds the string array.
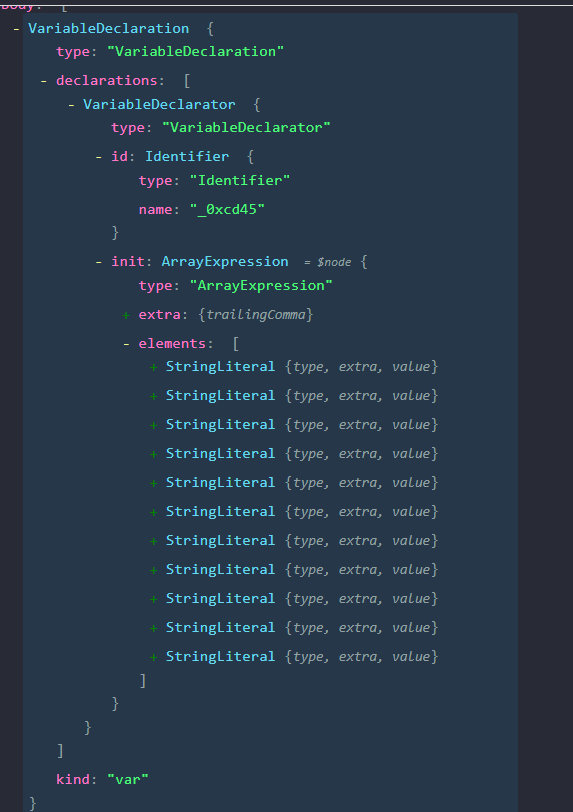
We can observe that the name of the string array,_0xcd45 is held in path.node.declarations[0].id.name. We can also see that path.node.declarations[0].init.elements is an array of nodes, which holds each node of the string literals declared in the string array. Finally, the string array is the first VariableDeclaration with an init value of type ArrayExpression encountered at the top of the file.
[Note: Traditionally, javascript obfuscators put the string arrays at the top of the file/code block. However, sometimes this may not always be the case (e.g. other string-containing arrays are declared first or reassignment of the string array). You may need to make a slight modification to this step in that case.]
Using those observations, we can come up with the following logic to restore the code:
Traverse the ast to search for the variable declaration of the string array. To check if it is the string array’s declaration, it must meet the following criteria:
- The VariableDeclaration node must declare only ONE variable.
- Its corresponding VariableDeclarator node must have an init property of type ArrayExpression
- ALL of the elements of the ArrayExpression must be of type StringLiteral
After finding the declaration, we can:
- Store the string array’s name in a variable,
stringArrayName - Store a copy of all its elements in a variable,
stringArrayElements
- Store the string array’s name in a variable,
Find all references to the string array. One of the most powerful features of Babel is it’s support for scopes.
From the Babel Plugin Handbook:
References all belong to a particular scope; this relationship is known as a binding.
We’ll take advantage of this feature by doing the following:
- To ensure that we are getting the references to the correct identifier, we will get the path of the
idproperty and store it in a variable,idPath. - We will then get the binding of the string array, using
idPath.scope.getBinding(stringArrayName)and store it in a variable,binding. - If the binding does not exist, we will skip this variable declarator by returning early.
- The
constantproperty ofbindingis a boolean determining if the variable is constant. If the value ofconstantis false (i.e, it is reassigned/modified), replacing the references will be unsafe. In that case, we will return early. - The
referencePathsproperty ofbindingis an array containing every NodePaths that reference the string array. We’ll extract this to its own variable.
- To ensure that we are getting the references to the correct identifier, we will get the path of the
We will create a variable,
shouldRemove, which will be a flag dictating whether or not we can remove the original VariableDeclaration. By default, we’ll initialize it totrue. More on this in the next step.We will loop through each individual
referencePathof thereferencePathsarray, and check if they meet all the following criteria:- The parent NodePath of the current
referencePathmust be a MemberExpression. The reason we are checking the parent node is because thereferencePathrefers to the actual referenced identifier (in our example,_0xcd45), which would be contained in a MemberExpression parent node (such as_0xcd45[0]) - The parent NodePath’s
objectfield must be the the current referencePath’s node (that is, it must be the string array’s identifier) - The parent NodePath’s
computedfield must betrue. This means that bracket notation is being used for member access (ex._0xcd45[0]). - The parent NodePath’s
propertyfield must be of typeNumericLiteral, so we can use it’s value to access the corresponding node by index.
- The parent NodePath of the current
If all of these criteria are met, we can lookup the corresponding node in our
stringArrayElementsarray using the value stored in the parent NodePath’spropertyfield, and safely replace thereferencePath‘s parent path with it (that is, replace the entire MemberExpression with the actual string).If at least one of these conditions are not met for the current
referencePath, we will be unable to replace the referencePath. In this case, removing the original VariableDeclarator of the string array would be unsafe, since these references to it would be in the final code. Therefore, we should set ourshouldDeleteflag to false. We’ll then skip to the next iteration of the for loop.After we have finished iterating over all the referencePaths, we will use the value of our
shouldRemoveflag to determine if it is safe to remove the original VariableDeclaration.
- If
shouldRemovestill has the default value oftrue, that means all referencePaths have been successfully replaced, and the original declaration of the string array is no longer needed, so we can remove it. - If
shouldRemoveis equal tofalse, we encountered a referencePath that we could not replace. It is then unsafe to remove the original declaration of the string array, so we don’t remove it.
The Babel implementation is shown below:
Babel Deobfuscation Script
1 | |
After processing the obfuscated script with the babel plugin above, we get the following result:
Post-Deobfuscation Result
1 | |
The strings are now deobfuscated, and the code becomes much easier to read.
Example #3: String Concatenation
This type of obfuscation, in its most basic form, takes a string such as the following:
1 | |
And splits it into multiple parts:
1 | |
You might be thinking, “Hey, the obfuscated version doesn’t look that bad”, and you’d be right. However, keep in mind that a file will typically have a lot more obfuscation layered on top. An example using the techniques already covered above could look something like this (or likely more advanced):
1 | |
The following analysis will only cover the most basic case from the first example I showed you. Traditionally, a file’s obfuscation layers are peeled back one at a time. Your goal as a reverse engineer would be to make transformations to the code such that it looks like the basic case and only then apply this analysis.
Original Source Code
1 | |
Post-Obfuscation Code
1 | |
Analysis Methodology
Let’s paste our obfuscated code into AST Explorer.
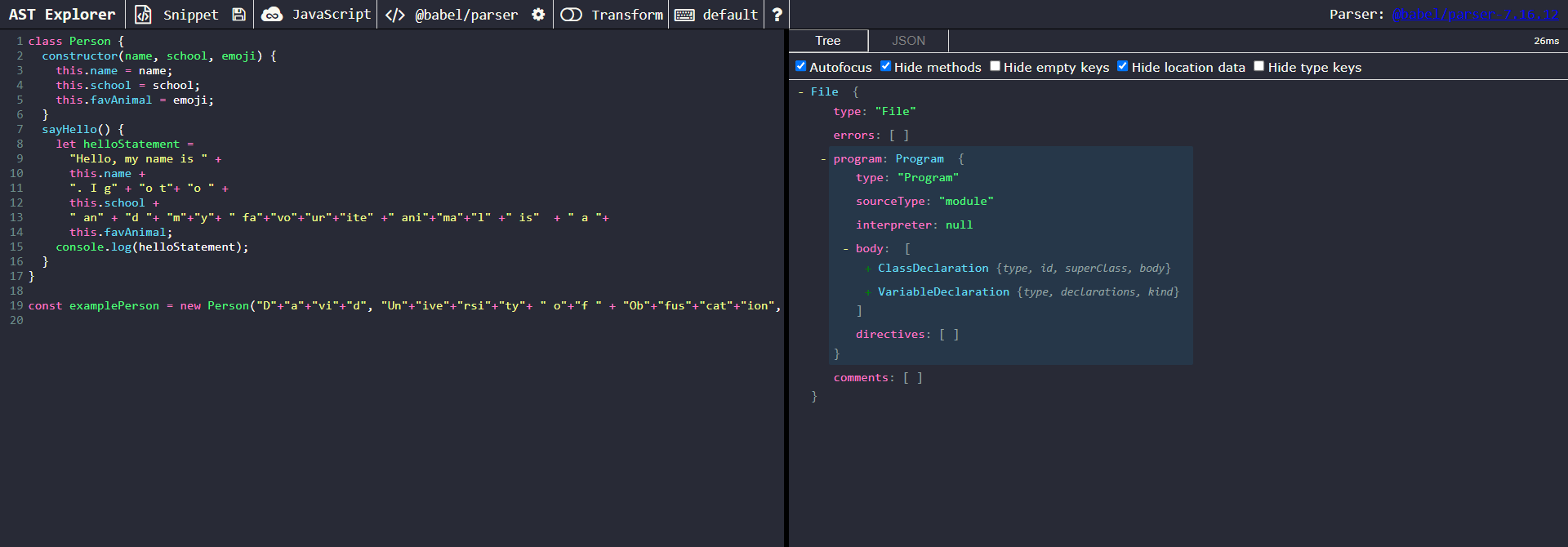
Our targets of interest here are all of the strings being concatenated. Let’s click on one of them to take a closer look at one of the nodes of interest.
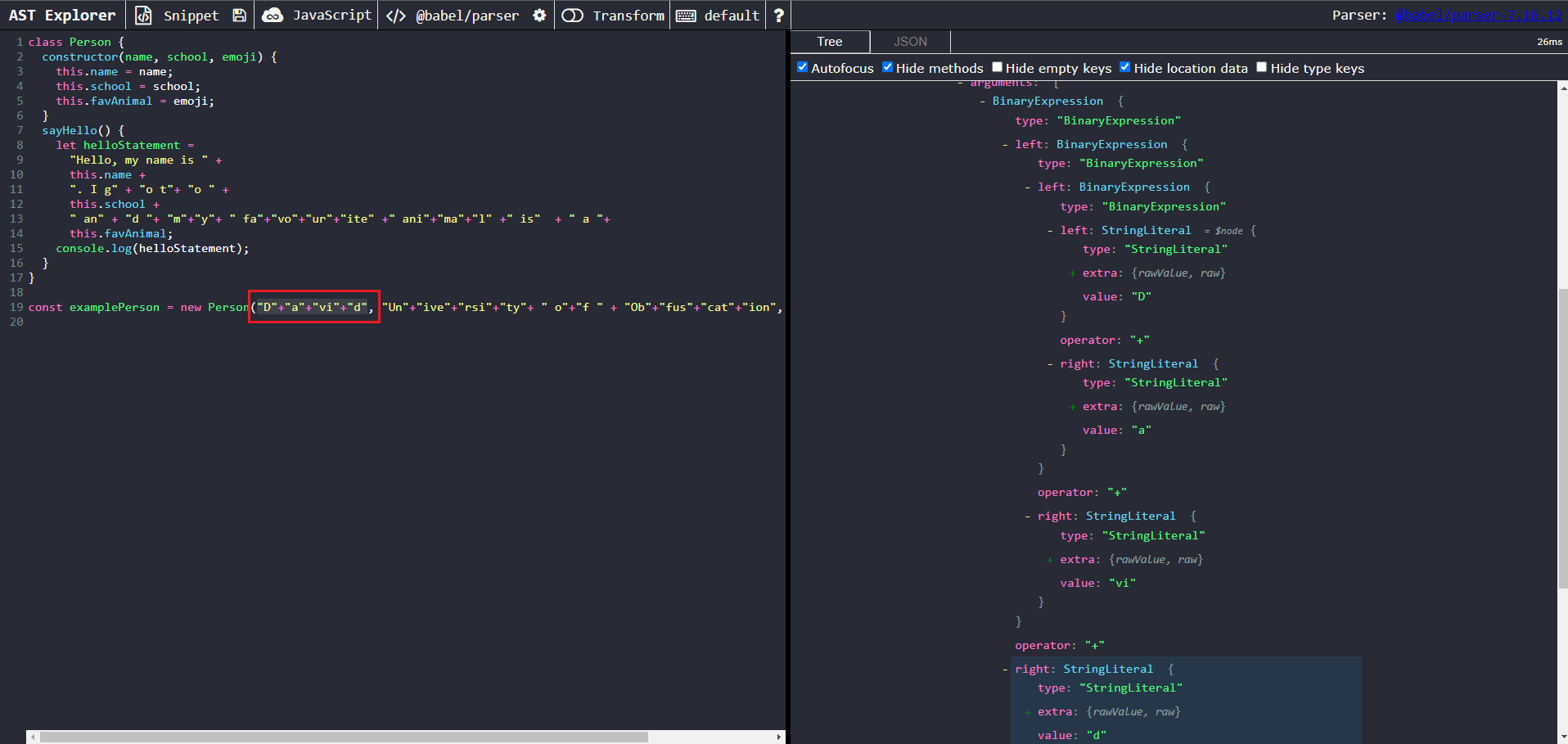
We can make the following observations from the AST structure:
- We can see that each individual substring is of type StringLiteral.
- More importantly, the string literals seem to be contained in multiple nested BinaryExpressions.
So how could we go about solving this?
There are a few ways to do this. One would be to work up recursively from the right-most StringLiteral node in the binary expression and manually concatenate the string at each step. However, there’s a much simpler way to accomplish the same thing using Babel’s inbuilt path.evaluate() function. The steps for coding the deobfuscator are included below:
- Traverse through the AST to search for BinaryExpressions
- If a BinaryExpression is encountered, try to evaluate it using path.evaluate().
- If path.evaluate returns confident:true, check if the evaluated value is a StringLiteral. If either condition is false, return.
- Replace the BinaryExpression node with the computed value as a StringLiteral, stored in value.
The babel implementation is shown below:
Babel Deobfuscation Script
1 | |
After processing the obfuscated script with the babel plugin above, we get the following result:
Post-Deobfuscation Result
1 | |
But hold on, that looks only partly deobfuscated!
A Minor Complication
Okay, I may have lied to you a bit. The example I gave you actually contains two cases. The simplest case with ONLY string literals:
1 | |
And the bit more advanced case, where string literals are mixed with non-string literals (in this case, variables):
1 | |
The above algorithm will not work for the second case as is. However, there’s a simple remedy. Simply edit the obfuscated file to wrap consecutive strings in brackets like so:
1 | |
And our deobfuscator will output our desired result:
1 | |
I’m sure some of you might be wondering why the algorithm doesn’t work without manually adding the brackets. This is outside of the scope of this article. However, if you’re interested in the reason for this intricacy and an algorithm that simplifies it without needing to manually add the brackets, check out my article about Constant Folding. But for now, I’ll move on to another example.
Example #4: String Encryption
First and foremost, string encryption IS NOT the same as encoding strings as hexadecimal or unicode. Whereas the javascript interpreter will automatically interpret"\x48\x65\x6c\x6c\x6f" as "Hello", encrypted strings must be passed through to a decryption function and evaluated before they become useful to the javascript engine (or representable as a StringLiteral by Babel).
For example, even though Base64 is a type of encoding, in the context of string concealing it falls under string encryption since console.log("SGVsbG8=") prints SGVsbG8=, but console.log(atob{SGVsbG8=}) prints Hello. In this example, atob() is the decoding function.
Most obfuscators will define custom functions for encrypting and decrypting strings. Sometimes, the string may need to go through multiple decryption functions Therefore, there is no universal solution for deobfuscating string encryption. Most of the time, you’ll need to manually analyze the code to find the string decryption function, hard-code it into your deobfuscator, then evaluate it for each CallExpression that references it. The example below will cover a single example that uses an XOR cipher from this repository for obfuscating the strings.
Original Source Code
1 | |
Post-Obfuscation Code
1 | |
Analysis Methodology
Let’s paste our obfuscated code into AST Explorer.
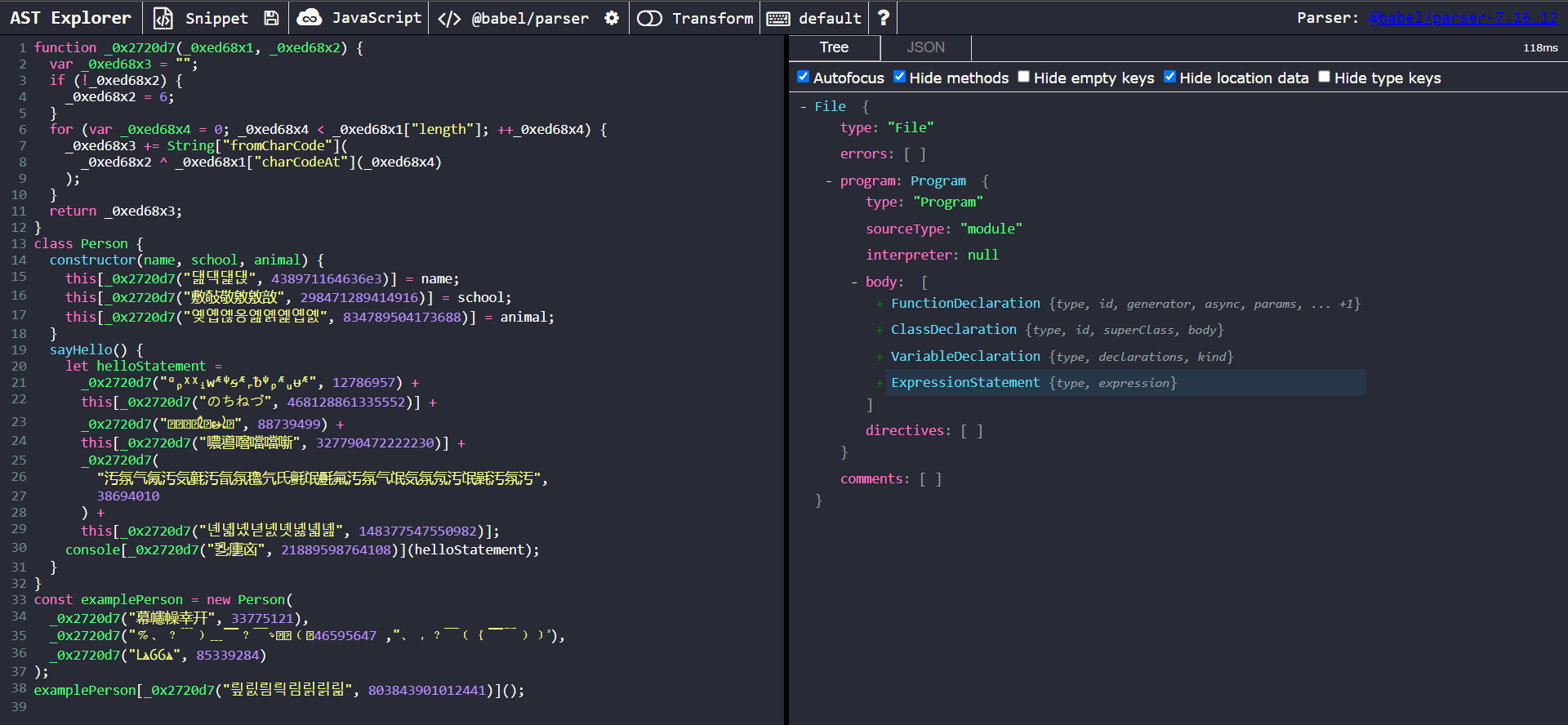
Our targets of interest here are the cryptic calls to the _0x2720d7 function. Let’s take a closer a closer look at one of them.
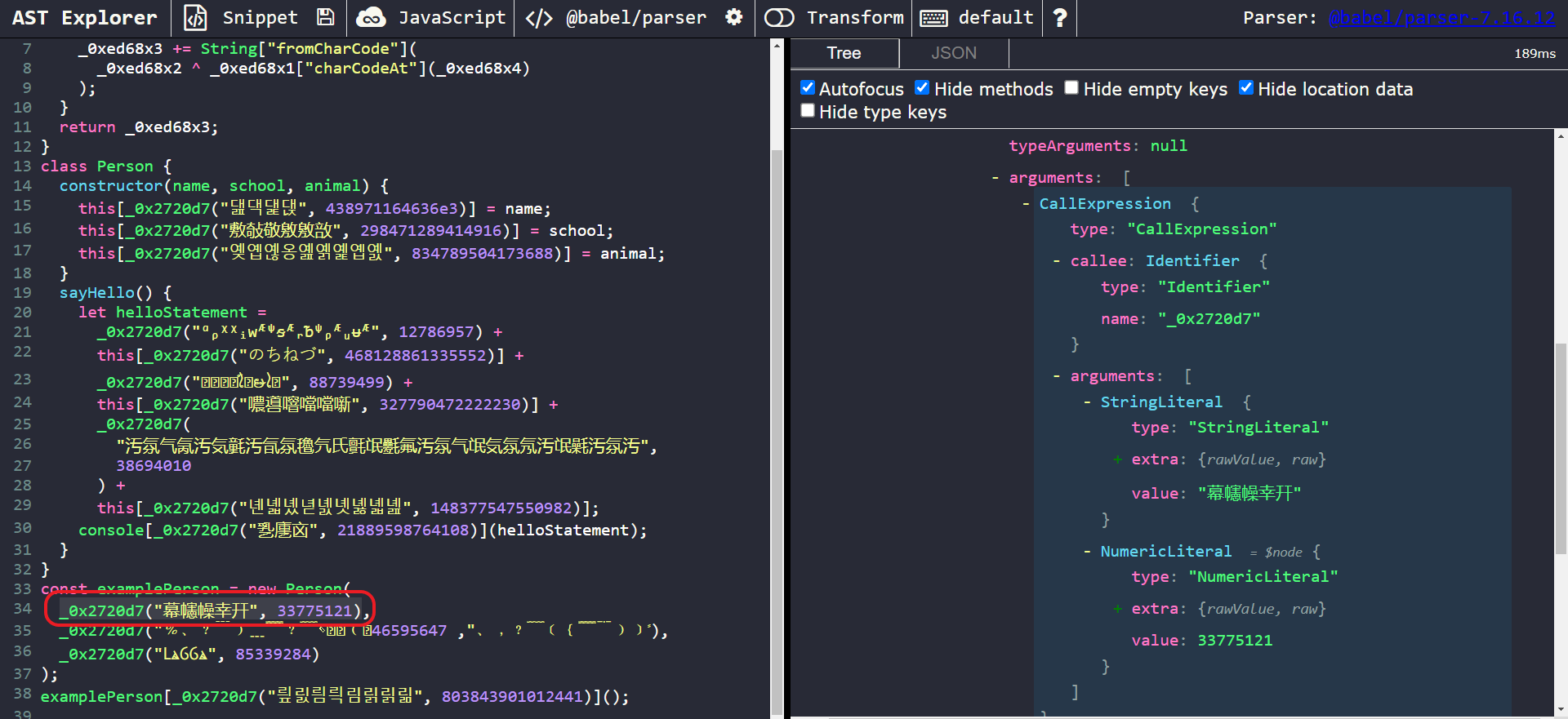
We can observe that the nodes of interest are of type CallExpression. Each call expression takes in two parameters. The first is a StringLiteral which holds the encrypted string. The second is a NumericLiteral, which is used as a decryption key.
There are two ways we can deobfuscate this script, the second of which I personally prefer since it looks cleaner.
Method #1: The Copy-Paste Technique
The first method involves the following steps:
- Find the decryption function in the obfuscated script
- Paste the decryption function,
_0x2720d7, in our deobfuscator - Traverse the ast in search for the FunctionDeclaration of the decryption function (in this case,
_0x2720d7). Once found, remove the path as it is no longer necessary - Traverse the ast in search of CallExpressions where the callee is the decryption function (in this case,
_0x2720d7). Once found:- Assign each arugument of
path.node.argumentsto a variable, e.g.stringToDecryptanddecryptionKeyrespectively. - Create a variable,
result - Evaluate
_0x2720d7(stringToDecrypt,decryptionKey)and assign the resulting value toresult - Replace the CallExpression path with the actual value:
path.replaceWith(t.valueToNode(result))
- Assign each arugument of
One of the reasons I don’t like to use this method is that the code for the deobfuscator can become quite long and messy if:
- The decryption function contains many lines of code, or
- There are many parameters to parse from the CallExpression
A cleaner approach in my opinion is the next method, which evaluates the decryption function and its calls in a virtual machine.
Method #2: Using the NodeJS VM module
Whenever possible, I prefer to use this method because of its cleanliness. Why? Well,
- It doesn’t require me to copy-paste the entire encryption function into my deobfuscator
- I don’t need to manually parse any of the arguments of CallExpressions before execution.
The only downside is that it requires two separate visitors and therefore two traversals, whereas you can probably implement the first method in a single traversal.
Here are the steps to implement it:
- Create a variable,
decryptFuncCtxand assign it an empty context usingvm.createContext() - Traverse the ast in search for the FunctionDeclaration of the decryption function (in this case,
_0x2720d7). Once found:- Use
@babel/generatorto generate the function’s source code from the node and assign it to a variable,decryptFuncCode - Add the decryption function to the VM’s context using
vm.runInContext(decryptFuncCode, decryptFuncCtx) - Delete the FunctionDeclaration node with
path.remove()as it’s now useless, and stop traversing withpath.stop()
- Use
- Traverse the ast in search of CallExpressions where the callee is the decryption function (in this case,
_0x2720d7). Once found:- Use
@babel/generatorto generate the CallExpression’s source code from the node and assign it to a variable,expressionCode - Evaluate the function call in the context of
decryptFuncCtxusingvm.runInContext(expressionCode,decryptFuncCtx). - Optionally assign the result to a variable,
value - Replace the CallExpression node with the computed value to restore the unobfuscated string literal.
- Use
Note: for both of these methods you should probably come up with a dynamic way to detect the decryption function (by analyzing the structure of the function node or # of calls) in case the script is morphing. You should also pay mind to the scope of function and also check if it’s ever redefined later in the script. But for this example, I will neglect that and just hardcode the name for simplicity.
The babel implementation for the second method is shown below:
Babel Deobfuscation Script
1 | |
After processing the obfuscated script with the babel plugin above, we get the following result:
Post-Deobfuscation Result
1 | |
The strings are now deobfuscated, and the code becomes much easier to read.
Conclusion
Phew, that was quite the long segment! That about sums up the majority of string concealing techniques you’ll find in the wild and how to reverse them.
Before I go, I want to address one thing (as a bonus of sorts):
After deobfuscating the strings, we can see that they’re restored to:
1 | |
But someone familiar with Javascript knows that the convention is to write it like this:
1 | |
The good news is, you can also use Babel to restore the traditional dot operator formatting in MemberExpressions. Read my article about it here!
If you’re interested, you can find the source code for all the examples in this repository.
I hope that this article helped you learn something new. Thanks for reading, and happy reversing!