An Introduction to Javascript Obfuscation & Babel
Introduction
Welcome to the first article in my series about Javascript deobfuscation. I won’t be going in-depth regarding practical deobfuscation techniques; that’ll be reserved for later articles. Rather, this post serves as a brief overview of the state of Javascript obfuscation, different methods of analysis, and provides resources to learn more about reverse engineering Javascript.
What is Obfuscation?
Definition
Obfuscation is a series of code transformations that turn human-readable code into something that is deliberately difficult for a human to understand, while (for the most part) still maintaining its original functionality. Code authors may choose to obfuscate their code for many reasons, including but not limited to:
- To make it harder to modify, debug, or reproduce (e.g. some javascript-based games or programs)
- To hide malicious intent (e.g. malware)
- To enhance security, i.e obscuring the logic behind javascript-based challenges or fingerprinting (e.g. ReCAPTCHA, Shape Security, PerimeterX, Akamai, DataDome)
Example
For example, the obfuscation process can convert this human-readable script:
1 | |
Into something incomprehensible to humans:
1 | |
Yet, believe it or not, both of these scripts have the exact same functionality! You can test it yourself: both scripts output
1 | |
to the console.
The State of Javascript Obfuscation
There are many available javascript obfuscators, both closed and open-source. Here’s a small list:
Open-Source
Closed-Source
For further reading on the why and how’s of Javascript Obfuscation, I recommend checking out the Jscrambler blog posts. For now, though, I’ll shift the topic towards reverse engineering.
How is Obfuscated Code Analyzed?
In general, most reverse engineering/deobfuscation techniques fall under two categories: static analysis and dynamic analysis
Static Analysis
Static analysis refers to the inspection of source code without actually executing the program. An example of static analysis is simplifying source code with Regex.
Dynamic Analysis
Dynamic analysis refers to the testing and analysis of an application during run time/evaluation. An example of dynamic analysis is using a debugger.
Static vs. Dynamic Analysis Use-Cases
Since static analysis does not execute code, it makes it ideal for analyzing untrusted scripts. For example, when analyzing malware, you may want to use static analysis to avoid infection of your computer.
Dynamic analysis is used when a script is known to be safe to run. Debuggers can be powerful tools for reverse engineering, as they allow you to view the state of the program at different points in the runtime. Additionally, dynamic analysis can be (and often is) used for malware analysis too, but only after taking proper security precautions (i.e sandboxing).
Static and dynamic analysis are powerful when used together. For example, debugging a script containing a lot of junk code can be difficult. Or, the code may contain anti-debugging protection (e.g. infinite debugger loops). In this case, someone may first use static inspection of source code to simplify the source code, then proceed with dynamic analysis using the modified source.
Introducing Babel
Babel is a Javascript to Javascript compiler. The functionalities included with the Babel framework make it exceptionally useful for any javascript deobfuscation use case, since you can use it for static analysis and dynamic analysis!
Let me give a short explanation of how it works:
Javascript is an interpreted programming language. For Javascript to be interpreted by an engine (e.g. Chrome’s V8 engine or Firefox’s Spidermonkey) into machine code, it is first parsed into an Abstract Syntax Tree (AST). After that, the AST is used to generate machine-readable byte-code, which is then executed.
Babel works in a similar fashion. It takes in Javascript code, parses it into an AST, then outputs javascript based on that AST.
Okay, sounds interesting. But what even is an AST?
Definition: Abstract Syntax Tree
An Abstract Syntax Tree (AST) is a tree-like structure that hierarchically represents the syntax of a piece of source code. Each node of the tree represents the occurrence of a predefined structure in the source code. Any piece of source code, from any programming language, can be represented as an AST.
Note: Even though the concepts behind an AST are universal, different programming languages may have a different AST specifications based on their capabilities.
Some practical uses of ASTs include:
- Validating Code
- Formatting Code
- Syntax Highlighting
And, of course, due to the more verbose nature of ASTs relative to plaintext source code, it makes them a great tool for reverse engineering 😁
Unfortunately, I won’t be giving a more in-depth definition of ASTs. This is for the sake of time, and since that’d be more akin to the subject of compiler theory than deobfuscation. I’d prefer to get right into explaining the usage of Babel as quickly as possible. However, I’ll leave you with some resources to read up more about ASTs (which probably offer a better explanation than I could muster anyway):
Wikipedia - Abstract Syntax Trees
How JavaScript works: Parsing, Abstract Syntax Trees (ASTs) + 5 tips on how to minimize parse time
How Babel Works
Babel can be installed the same way as any other NodeJS package. For our purposes, the following packages are relevant:
@babel/core This encapsulates the entire Babel compiler API.@babel/parser The module Babel uses to parse Javascript source code and generate an AST@babel/traverse The module that allows for traversing and modifying the generated AST@babel/generator The module Babel uses to generate Javascript code from the AST.@babel/types A module for verifying and generating node types as defined by the Babel AST implementation.
When compiling code, Babel goes through three main phases:
- Parsing => Uses
@babel/parserAPI - Transforming => Uses
@babel/traverseAPI - Code Generation => Uses
@babel/generatorAPI
I’ll give you a (very) short summary of each of these phases:
Stages of Babel
Phase #1: Parsing
During this phase, Babel takes source code as an input and outputs an AST. Two stages of parsing are Lexical Analysis and Syntactic Analysis.
To parse code into an AST, we make use of @babel/parser. The following is an example of parsing code from a file, sourcecode.js:
1 | |
You can read more about the parsing phase here:
Babel Plugin Handbook - Parsing
Babel Docs - @babel/parser
Phase 2: Transforming
The transformation phase is the most important phase. During this phase, Babel takes the generated AST and traverses it to add, update, or remove nodes. All the deobfuscation transformations we write are executed in this stage. This stage will be the main focus of future tutorials.
Phase 3: Code Generation
The code generation phase takes in the final AST and converts it back to executable Javascript.
The Babel Workflow
This section will not discuss any practical deobfuscation techniques. It will only detail the general process of analyzing source code. I’ll be using an unobfuscated piece of code as an example.
When deobfuscating Javascript, I typically follow this workflow:
- Visualization
- Analysis
- Writing the Deobfuscator
Phase 1: Visualization with AST Explorer
Before we can write any plugins for a deobfuscator, we should always first visualize the code’s AST. To help us with that, we will leverage an online tool: AstExplorer.net.
AST Explorer serves as an interactive AST playground. It allows you to choose a programming language and parser. In this case, we would select Javascript as the programming language and @babel/parser as the parser. After that, we can paste some source code into the window and inspect the generated AST on the right-hand side.
As an example, I’ll use this snippet:
1 | |
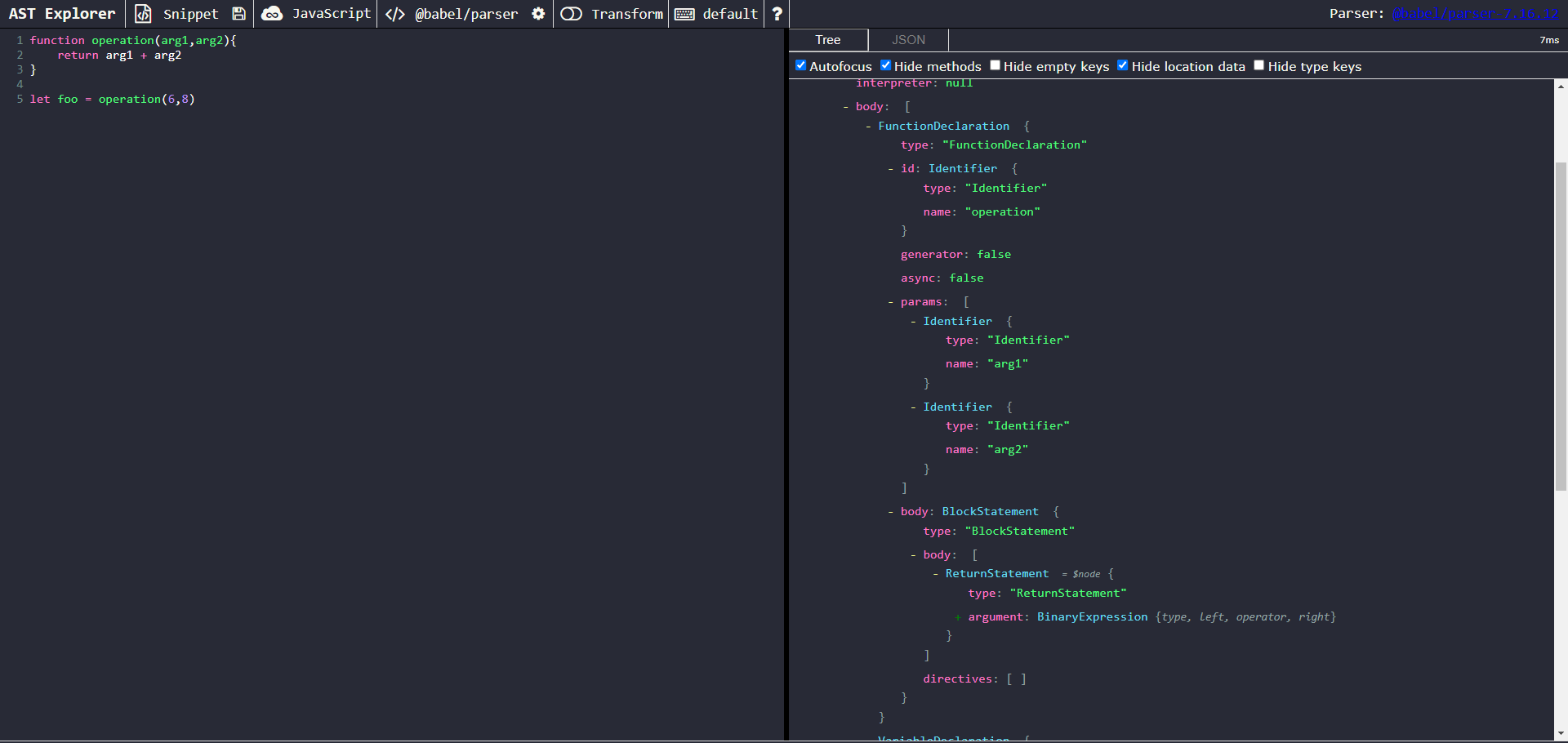
The generated AST looks like this:
Click to Expand
1 | |
We can observe that even for this small little program, the AST representation is incredibly verbose. It’s composed of different types of nodes (FunctionDeclarations, ExpressionStatements, Identifiers, CallExpressions, etc.), and many nodes also have a sub node. To transform the AST, we’ll be making use of the Babel traverse package to recursively traverse the tree and modify nodes.
Phase 2: Coming Up With The Transformation Logic/Pseudo-code
This isn’t an obfuscated file, but we’ll still write a plugin to demonstrate the traverse package’s functionality.
Let’s assign ourselves an arbitrary goal of transforming the script to replace all occurrences of arithmetic addition operators (+) with arithmetic multiplication operators (*). That is, the final script should look like this:
1 | |
Determining the Target Node Type(s)
First, we need to determine what our node type(s) of interest are. If we highlight a section of the code, AST explorer will automatically expand that node on the right-hand side. In our case, we want to focus on the arg1 + arg2 operation. After highlighting that piece of code, we’ll see this:
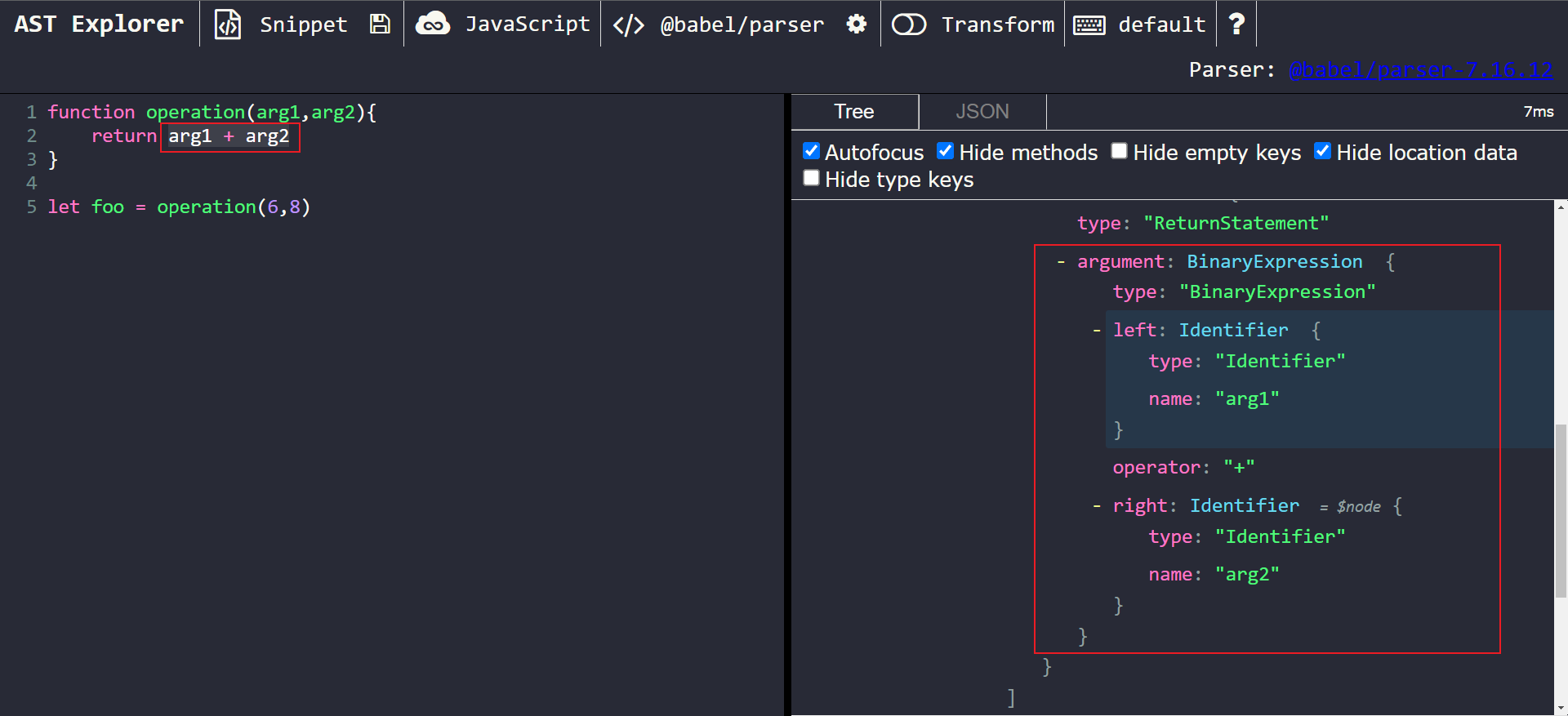
We can see that arg1 + arg2 has been parsed into a BinaryExpression node. This node has the following properties:
typestores the node’s type, in this case:BinaryExpressionleftstores the information for the left side of the expression, in this case: thearg1identifier.rightstores the information for the right side of the expression, in this case: thearg2identifier.operatorstores the operator, in this case:+.
Our goal is to replace all + operators in the script with a * operator, so it makes sense that our node type of interest is a BinaryExpression.
Now that we have our target node type, we need to figure out how we’ll transform them
Transformation Logic
To reiterate: we know that we’re looking for BinaryExpressions. Each BinaryExpression has a property, operator. We want to edit this property to * if it is a +.
The logical process would therefore look like this:
- Parse the code to generate an AST.
- Traverse the AST in search of
BinaryExpressions. - If one is encountered, check that its operator is currently equal to
+. If it isn’t, skip that node. - If the operator is equal to
+, set the operator to*.
Now that we understand the logic, we can write it as code
Phase 3: Writing the Transformation Code
To parse the tree, we will use the @babel/parser package as previously demonstrated. To traverse the generated AST and modify the nodes, we’ll make use of @babel/traverse.
To target a specific node type during traversal, we’ll use a visitor[https://github.com/jamiebuilds/babel-handbook/blob/master/translations/en/plugin-handbook.md#visitors].
From the Babel Plugin Handbook:
Visitors are a pattern used in AST traversal across languages. Simply put they are an object with methods defined for accepting particular node types in a tree.
To target nodes of type BinaryExpression, our visitor would like like this:
1 | |
Now, every time a BinaryExpression is encountered, the BinaryExpression(path) method will be called.
Inside the BinaryExpression(path) method of our visitor, we can add code for any checks and transformations.
Each visitor method takes in a parameter, path, which holds the path to the node being visited. To access the actual properties of the node, we must use path.node.
Our first step in our transformation would be to check that the operator property of the node is a +. We can do that like this:
1 | |
If it is a +, we can set it to *.
1 | |
And our visitor is complete! Now we just need to call it on the generated AST. But first, let’s generate the AST:
1 | |
After that, we can paste our visitor into the source code. To traverse the AST using the visitor, we’ll use the traverse method from the @babel/traverse package. That would look like this:
1 | |
Finally, we’ll use the generate method from the @babel/generator package to generate the final code from the modified AST. We can also output the resulting code to a file, but I’ll just log it to the console for simplicity.
So, our final transformation script looks like this:
Babel Transformation Script
1 | |
This will output the following to the console:
1 | |
And we can see that the code has been successfully transformed to replace + operators with * operators!
Why use Babel for Deobfuscation?
So, why should we use Babel as a deobfuscation tool as opposed to other static analysis tools like Regex?
Here are a few reasons:
Ast is less error-prone.
- For large chunks of code, writing transformations can become incredibly tedious due to the edge cases. For example, it’s difficult to account for the scope and state of variables when using regex. For example, two different variables can share the same name if they’re in different scopes:
1 | |
Eventually, regular expressions will become very convoluted when you have to account for edge cases; whether it be scope or tiny variations in syntax. Babel doesn’t have this problem, as you can use built-in functionality to make transformations with respect to scope and state.
The Babel API has a lot of useful features.
Here are a few useful things you can do with the built-in Babel API:
- Easily target certain nodes
- Handle scope when renaming/replacing variables
- Easily get initial values and references of variables
- Node validation, generation, cloning, replacement, removal
- Find paths to ancestor and descendant nodes based on test conditions
- Containers/Lists: Check if a node is in a container/list, and get all of its siblings
Good for static and dynamic analysis
- Inherently, parsing the code into an AST and applying transformations will not execute the code. But Babel also has the functionality to evaluate nodes (ex. BinaryExpressions) and return their actual value. Babel can also generate code from nodes, which can be evaluated with
evalor the NodeJS VM.
- Inherently, parsing the code into an AST and applying transformations will not execute the code. But Babel also has the functionality to evaluate nodes (ex. BinaryExpressions) and return their actual value. Babel can also generate code from nodes, which can be evaluated with
Conclusion + Additional Resources
That was a short demonstration of transforming a piece of code with Babel! The next articles will be more in-depth and include practical cases of reversing obfuscation techniques you might encounter in the wild.
For the sake of time, I didn’t go too deep into the behind-the-scenes of Babel or all of its API methods. In the future, I may decide to update this article or write a new one with more detailed explanations, examples, and documentation. But, I really recommend getting a solid fundamental understanding of Babel’s features before continuing on in this series. Most notably, I didn’t cover the usage of the @babel/types package in this article, but it will be utilized in future ones. I’d recommend giving these resources a look:
Official Babel Docs
Babel Plugin Handbook
Video: @babel/how-to
Here are links to the other articles in this series:
Deobfuscating Javascript via AST: Reversing Various String Concealing Techniques
Deobfuscating Javascript via AST: Converting Bracket Notation => Dot Notation for Property Accessors
Deobfuscating Javascript via AST: Constant Folding/Binary Expression Simplification
Deobfuscating Javascript via AST: Constant Folding/Binary Expression Simplification
Deobfuscating Javascript via AST: Replacing References to Constant Variables with Their Actual Value
Deobfuscating Javascript via AST: Removing Dead or Unreachable Code
You can also view the source code for all my deobfuscation tutorial posts in this repository
Okay, that’s all I have for you today. I hope that this article helped you learn something new. Thanks for reading, and happy reversing!